Lately I’ve been looking around distributed messaging systems. As the new kid on the block, I decided to start with Apache Kafka and I was surprised with how easy it is to start with the basics.
With Kafka,
- Producers push and Consumers pull messages.
- Messages are persisted (filesystem) and organized into topics.
- Topics can have multiple partitions (on different machines, if needed).
- Runs in clusters.
- Nodes/servers are called brokers.
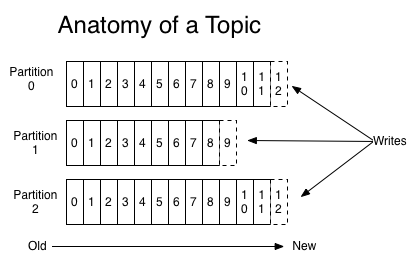
Each topic has it’s own offset which allows you to start consuming a topic from a specified offset. Every new message is added to the partition’s head and a specific message is identified by it’s partition, topic and offset. Kafka allows you to have multiple consumers consuming the same partition on the same topic, as messages are not removed once they are consumed. E.g. ConsumerA is consuming from the offset 3 and ConsumerB started consuming from the offset 3 but is currently reading from the offset 10, when ConsumerA reaches offset 10 he will have consumed the exact same messages as Consumer B.
Still, need to note that the persistence time is configurable. Kafka can persist the messages for a predefined amount of time, as in the previous example if ConsumerA takes too long to consume it may not consume the exact same messages. Kafka doesn’t keep a track of consumers, i.e. it is the consumer’s responsibility to keep track of what they have consumed and where they are currently in the topic (partition & offsets).
Each broker has one or more partitions and each partition has a leader. The consumers and producers only talk with the partition leader. The leader replicates the information with the followers.
Producers load balance the partition, i.e. producers randomly talk to the leader partitionA for an X amount of time. When that time expires the producer will select another leader to talk to. Still, it is possible to customise the load balancer by your needs.
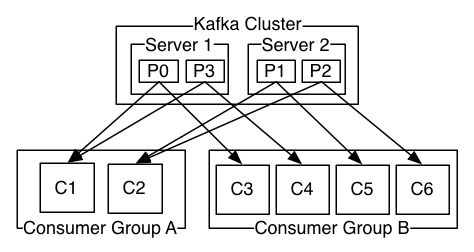
Consumers can be grouped, consumer groups. Each consumer takes a part of the data where the group as a whole does the work. This is handy for scaling, if a consumer is struggling to keep up with the work load you can fire up a new consumer to help out.
Ok, enough of cheap talking. Let’s get our hands dirty.
First you need to download Kafka and extract it to your server/computer. Kafka has binaries for Win and Linux systems. For both operation systems the procedure is quite the same, on Windows use “yourKafkaFolderLocation\bin\windows” folder.
First thing first, let’s have a look at the configuration file. Go to config folder and open up server.properties. The content is pretty much self explanatory. Each instance of Kafka requires it’s own .properties file. If you intend to run more than one instance of Kafka in your machine/server you need a copy of server.properties file and each .properties file has to have a unique broker.id and port number.
First, let’s create a topic by using the following command for Linux:
sh kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic HelloKafka
And for Windows:
kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic HelloKafka
To run Kafka you first need to have an instance of Zookeeper running. To do so, on the bin folder run the following command for Linux:
sh zookeeper-server-start.sh path-to-your-zookeeper-config-file
and for Windows:
zookeeper-server-start path-to-your-zookeeper-config-file
Once Zookeeper is up and running you can fire up Kafka, to do so on Linux run the following command:
sh kafka-server-start.sh path-to-your-kafka-config-file
and for Windows:
kafka-server-start path-to-your-kafka-config-file
Now that you can start an instance of Kafka let’s code a producer and a consumer.
For the producer, we need to set some configurations. We do so with the following method.
// Set the producer configuration
public void configureAndStart(ProducerType producerType) {
kafkaProperties = new Properties();
kafkaProperties.put("metadata.broker.list", brokerList);
kafkaProperties.put("serializer.class", "kafka.serializer.StringEncoder");
kafkaProperties.put("request.required.acks", "1");
kafkaProperties.put("producer.type", producerType.getType());
producerConfig = new ProducerConfig(kafkaProperties);
// Start the producer
producer = new Producer<String, String>(producerConfig);
}
Here we set the broker url, the message serializer, we wait for the leader’s acknowledgement after the leader replica has received the data and we specify the producer type (if it is a synchronous or an asynchronous producer).
More information about these and other possible configurations can be found here.
To produce a message into a Kafka’s topic we call the following method.
// Create the message and send it over to kafka
// We use null for the key which means the message will be sent to a random partition
// The producer will switch over to a different random partition every 10 minutes
public void produceMessage(String message) {
KeyedMessage<String, String> keyedMessage = new KeyedMessage<String, String>(topic, null, message);
producer.send(keyedMessage);
}
And that’s pretty much it.
On the consumer side we also need to set up some configurations. To do so, we use the following method.
/**
* Zookeeper to coordinate all the consumers in the consumer group and track the offsets
*/
public void configure() {
kafkaProperties.put("zookeeper.connect", zookeeperUrl);
kafkaProperties.put("group.id", groupId);
kafkaProperties.put("auto.commit.internal.ms", "1000");
kafkaProperties.put("auto.offset.reset", "largest");
// If you want to manually control the offset commit set this config to false
kafkaProperties.put("auto.commit.enable", "true");
// By default it waits till infinite otherwise specify a wait time for new messages.
kafkaProperties.put("consumer.timeout.ms", waitTime);
consumerConfig = new ConsumerConfig(kafkaProperties);
}
Then, we start the consumer by calling the start() method.
public void start() {
consumerConnector = Consumer.createJavaConsumerConnector(consumerConfig);
/**
* Define how many threads will read from each topic. We have one topic and one thread.
*
* Can be multi thread (one topic 2+ threads). With the high level consumer we usually don't multi thread them.
* This is because if I want to manually commit offsets it will commit for all the threads that have this
* consumer instance, at the same time. To avoid this we can create multiple consumer instances and have each
* of them their own thread.
*/
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, 1);
/**
* We will use a decoder to get Kafka to convert messages to Strings
* valid property will be deserializer.encoding with the charset to use
* default UTF8 which works for us
*/
StringDecoder decoder = new StringDecoder(new VerifiableProperties());
/**
* Kafka will give us a list of streams of messages for each topic.
* In this case it is just one topic with a list of a single stream
*/
stream = consumerConnector.createMessageStreams(topicCountMap, decoder, decoder).get(topic).get(0);
}
Whenever we want to fetch for messages we call the following method where we get a stream iterator. Using the iterator we retrieve the next message and return it.
public String fetchMessage() {
ConsumerIterator<String, String> it = stream.iterator();
try {
return it.next().message();
}
catch (ConsumerTimeoutException ex) {
System.out.println("Waited " + waitTime + " but no messages arrived... Exiting...");
return null;
}
}
Here is the output for the producer.

And here is the consumer output.

The full code can be found on my GitHub repository or by following this link.
For the sake of brevity and simplicity I followed the KISS principle. A lot more can be done with Kafka. I’ll try to come up with slightly more advanced use cases for Kafka in the future.